Welcome to the kriha.org weblog

- Speed - Webday at HdM
-

This years webday is all about speed: fast web applications and quick in-browser desing as well as the new WebRTC standard and its new audio-visual features. Daniel Kuhn and Michael Raith, CSM-Alumni and authors of "Performante Webanwendungen". (dpunkt Verlag) will show us, how to increase the performance of web applications considerably. And it is not really a secret anymore, that performance belongs to the core criteria for the usability and acceptance of websites and applications. The next topic deals with new ways to design web-applications: Especially mobile use of the Internet puts new pressures on web designers. Experts talk about the big change - going away from Photoshop towards "design-in-the-browser". The layout is no longer created in Photoshop. Instead, it it quickly and directly realized in HTML/CSS/JavaScript and finalized within the browser. The biggest obstacle to this approach is the high level of technical expertise now required by the designers. Jakob Schröter, CSM-Alumnus, HdM-Lecturer and product manager with rukzuk AG, will show alternatives to the classic web-design workflow. He will talk about the challenges behind the development of a web-based design software with integrated content management. Now designers can create websites without programming knowledge. Finally, some features from the new WebRTC standard will be shown and we will - together with the audience - discuss some possible applications. With the new protocols and interfaces, live video conferences and peer-to-peer realtime applications are just a couple of Javacript statements away.
Agenda: 13.30 Welcome Prof. Walter Kriha 13.35 - 14.35 "Performante Webanwendungen", M.Sc. Daniel Kuhn, M.Sc. Michael Raith 14.40 - 15.40 "Photoshop lügt! Design in the Browser", M.Sc. Jakob Schröter, zukzuk AG 15.45 - 16.30 Der neue WebRTC Standard - Peer-to-peer AV und Realtime Applikationen direkt im Browser, Aktuelle Themen Team und W.Kriha
Note
Friday January 10th, 13.30 - 16.30 at HdM, room 56. A live stream with chat is provided. As always, the event is free of charge and open to the interested public. Directions can be found at the hdm homepage.
- Multiparty Throwable Microphone, a mobile solution to capturing live discussions.
-
Capturing a live discussion during an event has always been a sore point for me. All my events (so called "days") are getting streamed to the internet. And while I have no problems with the talk itself (we use two wireless microphones), capturing the discussion when an audience is involved, is very hard. Currently I just run with a microphone to anybody who wants to say something. This is both tiring and a handicap for lively discussions. It just takes too long and does not allow a real discussion to start.

Aren't there any professional solutions for this problem? Of course there are. They are just, hm, professional. In other words: very expensive or simply impossible (like having your own studio with hundreds of microphones hanging from the ceiling). A typical suggestion is, to use long poles with microphones attached and hold them in front of anybody who wants to talk. (As seen on TV...). While this is certainly at least a mobile solution, it has the following small problem: I don't have the manpower.
Obviously, a cheap, mobile and multi-party solution was needed. The picture shows my idea of the "throwable multi-party microphone", implemented by Thomas Maier. A large conference room can - with the help of 8-10 of those balls - be turned into a place where everybody who wants to say something, can do so by requesting a microphone ball. The audience basically does the capture of the audio by itself. A small microcontroller or a PC allow advanced control over the microphones.
We have conducted some usability tests during two events and the results were very promising. The only change we would make, is to replace the tactile switch in the balls with a light-sensitive sensor. And now all that is left is to turn the prototype into a ruggedized design which can be inexpensively produced. The goal should be, to get 8-10 microphone balls and a small controller or PC interface for small money. The applications are basically endless. Streaming of events to the internet, discussions on public issues etc. The equipment would certainly much much cheaper than anything that is currently in use for those purposes.
Note
Please send me mail if you think you could produce the throwable microphones!
- Offline, Online and One-Pass - algorithmic lessons learned from High-Frequency Trading and others.
-
There was a time when batch processing large data collections - probably using some kind of map/reduce algorithm - was state of the art. All data were available for processing and time criticality was low. Index generation for search applications was an example for this type of processing. With the ever growing data collections, a size-problem manifested itself: New data showed up as a continuous feed and had to be processed, possibly in real-time and without having to go through all existing data. The online-algorithm was born and it allows incremental stream processing of incoming data. Google's percolator system was a replacement for map/reduce based index processing. Incremental algorithms became king. But, as two articles on High-Frequency-Trading from ACMqueue.org demonstrate. They would soon be replaced with something even faster: One-pass-algorithms. Such an algorithm does not touch input data twice. Nor does it need arrays of history data to go through. And it is designed to fit in the l1 cache of a CPU. A good example, taken from Loveless, Stoikov and Waeber, Online Algorithms in High Frequency Trading is the calculation of a moving Average. Average calculation involves summing up measurements and dividing by the number of measurements. In other words: going through arrays of data. A moving average inserts new measurements at one end of the array and removes older ones from the other side. Each measurement will have to be accessed several time, until it is retired. The average calculation can be changed into a two-pass algorithm with every new measurements being accessed exactly twice but still requires a larger memory array to be kept. This increases memory requirements and reduces cachability and therefore speed. A one-pass approximation for the moving average is the exponential moving average, where older data are included and weighted by a factor.
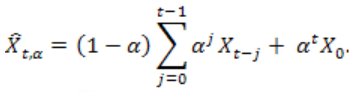
A one-pass algorithm basically consists of a value which presents the past, a factor which expresses the weight of the past data (in other words: how much the new measurement can influence the result) and the new measurement itself. The reason for this "need for speed" has been nicely expressed in Jacob Loveless, Barbarians at the Gateway - High Frequency Trading and Exchange Technology . You think milliseconds are fast? Think again. The "tick-to-trade" time is now around 50 microseconds. FPGAs are used to bring algorithms as close as possible to the data, without going through operating systems and layers of libraries. This is a development which comes surprisingly close to what Jeff Dean and Luiz Barroso of Google claim: That it is time to go through all the pieces of our computing infrastructure once again and remove all unneccessary buffering. I/O data which cannot be processed immediately because another application is currently busy are just one example of latency. HFT sure is an extreme example of realtime requirements, but I am sure, that we will see more and more of those types of processing in the future. The next king of data processing will be real-time. Followed perhaps by "everywhere".
- Large Fan-Out Architectures - now and then
-
Last week I stumbled over two excellent google papers and talks by Jeff Dean, " Achieving Rapid Response Times in Large Online Services" and Luiz Barroso, "Warehouse-Scale Computing: Entering the Teenage Decade" on current architectural problems, especially about large fan-out architectures and their latency problems. These problems are getting clear, when you look at the fanout diagram.
 Besides the huge number of connections needed - which asks for asynchronous I/O and the fact that the huge number of responses can easily clog your network and are hard on the receiving node, the core problem is the long tailed response time. Some servers will be slower due to hickups, uneven request runtimes etc. And because of the large number of subrequests, most of your requests will include some of these stragglers and end up with a much higher response time.
Besides the huge number of connections needed - which asks for asynchronous I/O and the fact that the huge number of responses can easily clog your network and are hard on the receiving node, the core problem is the long tailed response time. Some servers will be slower due to hickups, uneven request runtimes etc. And because of the large number of subrequests, most of your requests will include some of these stragglers and end up with a much higher response time. The problem is not exactly a new one. In 1999/2000 I was working on a portal architecture for a large international bank and experienced the bad effects of uneven latency in my design.
 A single-threaded request for the homepage would take roughly 3 minutes to complete, clearly asking for some substantial speed-up. After splitting the request into 12 or so subrequests, the response time was in the area of 30-40 seconds with a horrible variance. I used several of the measures Dean and Barroso recommend: I tried to bring the runtimes for each request to a similiar value. I tried to timeout requests to backend-servers in case the response was late. I did not use additional timed requests against replicas of slow services, something that would have been possible in at least one case. And I did not have asynchronous I/O at that time (Java 1.1) and this resulted in a large number of threads which - something I found out later - could only run on one CPU in our multiprocessor, as Java VM did not support multiple cores.
A single-threaded request for the homepage would take roughly 3 minutes to complete, clearly asking for some substantial speed-up. After splitting the request into 12 or so subrequests, the response time was in the area of 30-40 seconds with a horrible variance. I used several of the measures Dean and Barroso recommend: I tried to bring the runtimes for each request to a similiar value. I tried to timeout requests to backend-servers in case the response was late. I did not use additional timed requests against replicas of slow services, something that would have been possible in at least one case. And I did not have asynchronous I/O at that time (Java 1.1) and this resulted in a large number of threads which - something I found out later - could only run on one CPU in our multiprocessor, as Java VM did not support multiple cores.But the case shows, that innovative solutions simply come from tinkering with large platforms and the performance and latency problems they cause. Dean and Barroso add some more hints on how to deal with variance in latencies: Run a mix of all applications and services on every machine. Do not randomize special workload situations e.g. caused by batch processing, as it will only affect a much larger time range. Do partition data into many smaller partitions and host lots of them on one machine to distribute load and requests better. I am not so sure about running all kinds of code on all servers. I suspect, that at least the chubby locking clusters will be exempt from this rule: a distributed, quorum based consensus algorithm like Paxos, does not really like larger latencies, as they will cause reconfiguration due to suspected master nodes.
- Blackout - on the role of IT in smart energy grids
-

During my research term I have done some thinking on smart energy grids. Actually, it started already two years ago, concentrating on security issues back then. I did a talk on security at the Smart Grids Week 2013 in Salzburg, and the responses I got made me think some more on the role of IT in this area. During the conference I was able to draw some parallels (both technical and social) between IT (especially the Internet) and the energy world. My talk on security was received with some kind of disbelief and scepticism as to the sorry state of software security depicted by me. Looks like the trust that the traditional electrical engineering culture put in IT had been shattered a bit.
Anyway, the conference was extremely interesting and I decided to follow up on some of the ideas. My talk on Blackout - On the role of IT in Smart Energy Grids" was one of the results, next to planning an IT-Security conference on critical infrastructure, applying for an energy oriented smart games project and other activities around secure software and systems.
But the main driver was to investigate model analogies between IT and power engineering. These types of models are described in the book on Think Complexity by Alan Downey as "holistic models". The goal is to find similiar patterns in two models - and also the places where the models do not fit. And the talk is exactly about this: model similiarities and dissimilarities in both cultural and technical areas.
Finally, a new model for a cell-based, highly connected ecosystem of rather autonomous, mostly stochastically controlled energy grids will emerge, based on physics, needs of the society and some business orientation on top of it. With IT being the connection between physics and markets.
BTW: If you think about buying a power generator after the talk - make sure it is one with an inverter to keep the voltage levels close to the standard. Otherwise your laptops and other power sensitive machinery in your house will suffer badly (:-)
Note
Wednesday 27th November, 17.45 at HdM, room 011. As always, the event is free of charge and open to the interested public. Directions can be found at the hdm homepage.
- Recommender Day at HdM - individualized commercials through clever algorithms
-

How does Amazon know what we want? Sometimes, commercials are not as obnoxious and a bother as usual. This is, when we get something offered, that we might like. Individual, customized commercials are the goal of recommender systems. They combine the analysis of customers with an analysis of goods and predict the utility of certain items for customers. There is no psychology or sociology involved - just statistics and machine learning algorithms. But recommender systems go beyond mere shopping support. They learn what kind of movies we like, what kind of music we like to here and much more. They changed the way commercials work nowadays. And they are a perfect fit for the endless shelves of online-businesses. They might even change the professional skills needed for a successful carreer in marketing: From MBA to PHD in mathematics or computer science. With three talks we will lift the hood of recommender technology. First, Dominik Hübner, M.Sc., Quisma GmbH, München, gives an introduction to advanced recommender technology. E.g. how to deal with very popular products or the use of map/reduce algorithms to find interesting fits. Can extended search engines help finding optimal recommendations? Multi-modal recommendations try to find items with a good fit for certain customers AND a high probability of being bought. The talk is based on a master thesis at Quisma GmbH, Munich. Tobias Kässmann, M.Sc. will present his work at shopping24 - the evaluation of a recommendation system based on clustering und a newly developed product vector. Problems and solutions based on other techniques are discussed as well. Finally, Nicolas Drebenstedt, cand. B.Sc., shows how recommendations for news can be created and delivered in real-time at zeit online. Relevant proposals need to fit to the individual interests of readers as well as represent current developments in certain areas. Millions of daily visitors provide a challenge for those systems.
Agenda: 14.00 Welcome, Prof. Dr. Johannes Maucher, Prof. Walter Kriha 14.05 Dominik Hübner M.Sc., Techniken der maschinellen Recommendation, Quisma GmbH München 15.30 Tobias Kässmann M.Sc., Computer Science and Media, HdM, Ein Empfehlungssystem für shopping24 17.00 Nicolas Drebenstedt, cand. B.Sc. Medieninformatik, HdM, Echtzeit-Empfehlungen für ZEIT ONLINE. 17.30 Wrap-Up
Note
Friday 29th November, 14.00 - 17.00 at HdM, room 56. A live stream with chat is provided. As always, the event is free of charge and open to the interested public. Directions can be found at the hdm homepage.
| $Date: 2013/01/01 14:07:15 $ | Home | About... | Privacy... | Feedback |
Copyright © 2001-2015  Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution 2.5 License by Walter Kriha. Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution 2.5 License by Walter Kriha. | ||