Welcome to the kriha.org weblog

James R. Beniger, The Control Revolution 
- Taming Javascript
-
The "Caja" project (pron. "caha") is trying to turn a subset of Javascript into a so called object-capability language. The project page at google contains some very interesting examples (e.g. stealing cookies, injecting script, expose history) which are prevented by Caja. The specification is only around 30 pages and gives an idea what object capabilities are and how they can be used to "tame" a language.
The core idea behind this approach is to allow software extensions to be loaded but to run them in a very restricted environment by offering them a runtime container filled with very specific objects. I am saying objects here an not rights as in an object capability system there is no difference between the two. The surrounding environment - by injecting external objects into the container and making them available as so called "imports" restricts the authority of the extension code to exactly those objects.
The whole concept is NOT using identity based access control which is certainly a good thing. But the question is: if Javascript with its very powerful features (it is a lambda language after all) is really the right candidate for such an approach. It takes a lot of re-writing of Javascript code to prevent access to internal object members, to avoid the later addition of functions which can extract secret values and so on. But the result of this re-writing is surprisingly compatble with existing code.
Google, Yahoo and others seem to start using Caja already and a possible candidate which really should take a close look at Caja is eBay: it integrates code from power sellers into client pages and by doing so exposes them to all kinds of attacks. All it takes is one compromised power seller account (or one built just for that purpose) to endanger a lot of clients.
Anyway, I recommend reading the spec. and trying the examples. (We noticed a lot of different behavior from browsers when running those examples - especially safari). Looks like the will be no end to browser differences. Not its the Javascript...
- 7th IBM Day at HDM - Cloud Computing, MDD and Enterprise Architecture Management
-
 The world of IT is in continuous motion: large applications demand more and more performance, huge social networks try to scale with computing clouds and development leverages the generation of software from models.
The world of IT is in continuous motion: large applications demand more and more performance, huge social networks try to scale with computing clouds and development leverages the generation of software from models.  Last but not least the demands on proper documentation and management increase as well. But how does all this work behind the scenes? If you want to know how cloud computing works, how projects get developed using a model-driven approach, what's behind EA management and how to speed up J3EE or .NET then you should visit us on Friday 18.12.2009. Beginning at 14.00 technical experts from IBM will explain current trends and developments in computer science and information technology.
This is already the 7th time that HDM is hosting this technical event and our gratitude goes to Bernard Clark for taking the time and effort to organize it.
Last but not least the demands on proper documentation and management increase as well. But how does all this work behind the scenes? If you want to know how cloud computing works, how projects get developed using a model-driven approach, what's behind EA management and how to speed up J3EE or .NET then you should visit us on Friday 18.12.2009. Beginning at 14.00 technical experts from IBM will explain current trends and developments in computer science and information technology.
This is already the 7th time that HDM is hosting this technical event and our gratitude goes to Bernard Clark for taking the time and effort to organize it.
 Enterprise Architecture has started to merge with business architectures into a new, combined and integrated view on processes, componentes etc. This makes Enterprise Architecture management and documentation already mission critical. But there is also a strong movement towards better management of basically all artifacts (records, requirements etc.) and EA management is another building block in the corporate architecture.
Enterprise Architecture has started to merge with business architectures into a new, combined and integrated view on processes, componentes etc. This makes Enterprise Architecture management and documentation already mission critical. But there is also a strong movement towards better management of basically all artifacts (records, requirements etc.) and EA management is another building block in the corporate architecture.Using practical experiences from a large-scale project, Michael Lorenz will show us the advantages of a common documentation tool and approach.
 Model-driven software development supposedly has enormous potential - if it can be unlocked! Niko Stotz will discuss some of the reasons why adoption has started slow and is speeding-up now. He will explain the challenges of Model-Driven-Development in a real project and how you can overcome those challenges. The project he is showing uses open source MDD tools and you can use it for your own experiments.
Model-driven software development supposedly has enormous potential - if it can be unlocked! Niko Stotz will discuss some of the reasons why adoption has started slow and is speeding-up now. He will explain the challenges of Model-Driven-Development in a real project and how you can overcome those challenges. The project he is showing uses open source MDD tools and you can use it for your own experiments.This is probably also a good opportunity to discuss the future of software development in Germany (My Job Went to India: And All I Got Was This Lousy Book) and how model-driven technology will affect out-sourcing, off-shoring etc.
 Cloud Computing is one of the buzz-words of IT since about two years. Corporations need more and more flexibility in the way they react on changing demands (and that demand is not always growing...). Companies like Google, Amazon, Microsoft and others are spending a half a billion dollars on new data centers each. Common terms in cloud computing are "platform as a service" or "infrastructure as a service". "Software as a Service" is another alternative in this confusing techno-economic soup. Peter Demharter (well known at HDM from his talk on IPv6) will explain what IBM sees as Cloud Computing and Dynamic Infrastructure. An opportunity to ask about security, cost vs. performance etc.
Cloud Computing is one of the buzz-words of IT since about two years. Corporations need more and more flexibility in the way they react on changing demands (and that demand is not always growing...). Companies like Google, Amazon, Microsoft and others are spending a half a billion dollars on new data centers each. Common terms in cloud computing are "platform as a service" or "infrastructure as a service". "Software as a Service" is another alternative in this confusing techno-economic soup. Peter Demharter (well known at HDM from his talk on IPv6) will explain what IBM sees as Cloud Computing and Dynamic Infrastructure. An opportunity to ask about security, cost vs. performance etc.
Note
Feel free to join us at this (free) event. You will get an overview of what is currently happening in information technology and you will be able to discuss the consequences and problems. If you can't be here in person you might want to watch the IBM Day at http://days.mi.hdm-stuttgart.de. Live-Stream is available. Friday, 18.12.2009, 14:00 Uhr - 18:30 Uhr, room 65 Hochschule der Medien, Nobelstrasse 10, Stuttgart Directions
Agenda: 14:00 - 14:10 Welcome, Bernard Clark, Walter Kriha 14:10 - 15:10 Michael Lorenz: EA Management Methodik - Dokumentation 15:10 - 15:25 Break 15:25 - 16:25 Peter Demharter: Cloud Computing 16:25 - 16:40 Break 16:40 - 17:40 Niko Stotz: Projekterfahrung mit modellgetriebener Softwareentwicklung 17:40 - 17:50 Wrap-up, Bernard Clark, Walter Kriha
- In Defense of Computer Games
-
Last Thursday Norman, me and a group of my students did a presentation on positive aspects of computer games at a seminar in Bartholomä. Media and network specialists as well as teachers were discussing the effect of computer games especially on young people. This is my presentation on positive aspects of computer games.During the presentation I have shown short video snippets from Crysis, Assassins Creed etc. to demonstrate the realism and art of current games. The presentation ended with a live demo of Guild Wars and Crysis.
I hope I was able to show that playing games does not turn you into an idiot and that much can be learned by playing games. Game technology can be used successfully in scientific projects as well. Finally, the way the media are currently treating computer games is questionable: instead of focusing on weapons which really kill the media are putting all the blame for social problems on games. And even public broadcast channels like ZDF use unfair tricks to manipulate viewers. Take a look at "the two faces of ZDF" where they used one and the same material to produce two radically different features for different viewer populations or the staged action against killer games in Stuttgart.
For us one important conclusion resulted from the event in Bartholomä: we need to produce a feature on positive aspects where we show sequence by sequence what computer games can teach us and we need to show the way media are currently manipulating the reception of computer games.
- Keep on Gaming - 6th Games Day at HDM
-
 Massively Multiplayer Online Games (MMOGs)
like World of Warcraft" and Eve-Online attract and keep millions of
players. How can game vendors deals with such massive traffic and
performance requirements? Andreas Stiegler of HDM will show how the
clever combination of feature management, content mapping and huge
technical infrastructures leads to a pleasant experience in spite of
large numbers of users.
Massively Multiplayer Online Games (MMOGs)
like World of Warcraft" and Eve-Online attract and keep millions of
players. How can game vendors deals with such massive traffic and
performance requirements? Andreas Stiegler of HDM will show how the
clever combination of feature management, content mapping and huge
technical infrastructures leads to a pleasant experience in spite of
large numbers of users.Oliver Korn of Korion will talk about professional game development in the industry and Clemens Kern of HDM will explain the critical role of Realtime Lightning in high-end games.
Isolde Scheurer of HDM will present experiences from working many years on games and in the game industry.
During and between the talks there will be lots of opportunities for discussions with game developers or for active participation in the Wii Mario-Kart competition.
Computer games seem to have become the scapegoats of critical developments in society. Only recently the bavarian teachersassociation in collaboration with the well-known game critic Prof. Pfeiffer told everybody that gaming is responsible for poor performance at school . The experience at the Computer Science and Media faculty at HDM seems to contradict such statements: gamers and game developers frequently show excellent performance in their studies. And a recently started research project at HDM is using advanced game technology to build useful and usable virtual worlds for research in nanotechnology . A small workshop run by Valentin Schwind (Valisoft/HDM) and Norman Pohl (chief architect of the project at HDM) will give an introduction into this exciting application of game technology and explain why we think that gamers bring a very special and rare gift to software development.
Note
30. Oktober 2009, 14.15 Uhr at Hochschule der Medien Stuttgart, Nobelstrasse 10, 70569 Stuttgart, room 056 (Aquarium). The event is open to the interested public and free of charge. Live-stream and live-chat are available on the Gamesday Homepage .
- The Power of Nightmares
-
Sebastion Roth pointed me to "The Power of Nightmares: The Rise of the Politics of Fear". It is a BBC documentary in three parts on how the neo-conservatives created fear to get the funding and political support for their aggressive agenda. It does not start with 9/11. At least in my opinion the military industry and the military itself worked hard after the fall of the Soviet Union to create a new enemy.
You can download the series from the Internet Archive
Interstingly, the series was never allowed to run in the US...
- Socio-technical approaches to security and privacy
-
Computer.org magazine in its current edition has a number of articles on security, safety and privacy related technologies. One article by Simon Moncrieff et.al. deals with restricting public surveillance to the necessary minimum. The authors suggest a combination of data-hiding (scambling faces like in google streetview) and context-sensitive authorization (law-enforcement: full, others: fewer details etc.). The discussion shows how difficult data protection is once the data have been collected. All authorization done works only "after the fact" that the data have been taken and are physically available.
To make matters worse video observaillance got much more powerful due to its digitalization:
Resolution up and size of cameras down Easy persistence on huge digital stores Advances in automatic indexing and retrieval KI-supported search Fully connected cameras via IP We do not have a technical solution for privacy protection once the data have been taken. Only a socio-technical solution envolving some kind of technical details (obfuscation, anonymization, DRM), laws and processes protected through policies are possible. But one should not forget that authority involves causality: Things which are not recorded do not need protection!
Another interesting article comes from Bertran Meyer of Eiffel fame. He and his team are working on automatied test case generation from contracts (pre- and postcoditions) in software. It sounds nice to generate oracles (things which can tell that a certain test was OK or not) from semantic annotations in the code but I do not understand how this could generate all test cases needed. In my understanding contracts between callers and callees only define ranges of valid results. Say the result is a city in western europe. But is it the right city? Or the result must be between 10 and 20 - but is 14 OK or 15? I guess I will have to take a closer look at this.
Finally, the article by Abriel from ETH Zurich claims that flawless software is possible. His approach involves very detailed and strong requirements capture, a continuous horizontal and vertical refinement which finally leads to programs. And a system model based on doscrete transition systems. He also claims that no domain specific languages for system modelling in needed: classic set theory will do. Hmm. At least he acknowledges that his statements will raise some opposition in the applied camps.
- Critical Infrastructure Protection (CPI) and the illusion of cyber-terrorism
-
Last summer at the University of Freiburg we have discussed so called "Critical Infrastructure" and its protection within a kolloquium on security and society chaired by Stefan Kaufman. CPI has become popular in the US especially after 9/11. It consists of a long list of industries and branches and their IT infrastructures which are considered "critical" for the functioning of state, economy and society. And it is a very interesting concept indeed as most of this "critical" infrastructure is privately owned and not under direct control of the state.
Some may see this as a problem to enforce security measures, others have grown used to the privatization of security anyway and see this mostly as a problem of providing financial incentives for the corporations.
To me CIP has several facets as well. The first one is its power to uncover the lies of e.g. nuclear power companies on the safety of their plants. In the context of CIP discussions it became clear that those plants are not at all safe from terrorist attacks or even simple accidents - contrary to the statements given earlier by the corporations.
CIP does also have the power to generate a lot of funding for security companies. For other companies it allows an opportunity to hide information for reasons of "security".
But lastly and most important the concept of CIP has its focus completely wrong: Why are networks considered critical? Given the distributed nature of e.g. the Internet, networks are rather hard to destroy.And going through the list of so called critical infrastructure examples I can hardly see much danger on a national level. It takes the additional and completely crazy concept of cyber-terrorism to see anything critical in our everyday IT infrastructures. Some damage could be done but this damage would hardly be critical. Power grids have seen some crashes due to badly managed Windows based administration stations which became susceptible to viruses and other forms of malware attacks. As Bruce Schneier says: there is cyber crime which needs to be fought, but there is no cyber terrorism (outside of the media ).
The concept of CIP is so wrong that - applied e.g. to the financial industry - it turns out to be quite funny: The financial industry is also on the list of critical infrastructure, but it is not the FUNCTION of this industry (giving credit to companies e.g.) that is deemed critical. It is their NETWORKS which are considered as being of national import. What a nonsense considering the current financial crisis. This crisis was not caused by terrorists breaking the financial networks - quite contrary it looks like the terrorists were already sitting within the boards and steering committees of those organizations...
The reason behind the frequent mentioning of cyber terrorism and critical infrastruture together with the omonous warnings from security organizations is rather simple: both corporations from the security-industrial complex as well as state organizations responsible for security topics derive huge profits by creating FUD on supposed threats.
- Kontrollverluste
-
If you can read german books as well I'd recommend taking a look at "Kontrollverluste".
 A book by "Leipziger Kamera" on the
various ways surveillance is done in the BRD. But it is not just a
negative book. It shows e.g. clearly that the law is still a major
barrier against overboarding security demands of states and
companies. The dubious practice of "private-public partnerships" in
the security area is also discussed.
A book by "Leipziger Kamera" on the
various ways surveillance is done in the BRD. But it is not just a
negative book. It shows e.g. clearly that the law is still a major
barrier against overboarding security demands of states and
companies. The dubious practice of "private-public partnerships" in
the security area is also discussed. - The militarization of internal security - The NeoConOpticon Study
-
The Transnational Institute and statewatch.org recently published Ben Hayes study on current and future security goals for Europe called NeoConOpticon
 - in reference to the famous
"panopticon" prison where the wards have full and total control over
the inmates without being seen.
- in reference to the famous
"panopticon" prison where the wards have full and total control over
the inmates without being seen.The report explains many security concepts which have been ported from military use to internal state security: crowd control, full spectrum dominance, surveillance etc. And it shows how the decisions on european research in the security area is dominated by large corporations from the military-industrial complex. We are talking 1.4 billions of research funding here.
The most depressing part of the study shows us that decisions on security funding and security research in the EU are made without public involvement. This goes further than you would believe: to satisfy formal requirements on the involvement of civil organizations and NGO the corporations have created dummy organizations which now participate "for the public" in committees.
- The end of software engineering?
-
Big minds in computer science have over the years developed second thoughts on some of their core statements. Bruce Schneier withdrew his statement on "if the math is OK security is no problem" and stated that the real security problems have nothing to do with mathematics. And Tom deMarco just wrote an article on Software Engineering - an ideas whose time has come and gone? (thanks to Bernhard Scheffold for the link) where he rethinks his statement on "only what can be measured can be controlled". (this statement is actually still quite hot in neoliberal circles talking quality improvment etc.). But deMarco noticed some disturbing things in software projects which follow good (i.e. controlled) software engineering process.“"This line contains a real truth, but I've become increasingly uncomfortable with my use of it. Implicit in the quote (and indeed in the book's title) is that control is an important aspect, maybe the most important, of any software project. But it isn't. Many projects have proceeded without much control but managed to produce wonderful products such as GoogleEarth or Wikipedia. To understand control's real role, you need to distinguish between two drastically different kinds of projects: Project A will eventually cost about a million dollars and produce value of around $1.1 million. Project B will eventually cost about a million dollars and produce value of more than $50 million. What's immediately apparent is that control is really important for Project A but almost not at all important for Project B. This leads us to the odd conclusion that strict control is something that matters a lot on relatively useless projects and much less on useful projects. It suggests that the more you focus on control, the more likely you're working on a project that's striving to deliver something of relatively minor value. To my mind, the question that's much more important than how to control a software project is, why on earth are we doing so many projects that deliver such marginal value?"”
Looking back at the last ten years of working in the industry I can only confirm his observation: the tighter companies follow ITIL or other process technologies in software engineering, the less "chaotic" software projects behave - but the results are frequently very "conservative" to put it politely.
“"Consistency and predictability are still desirable, but they haven't ever been the most important things. For the past 40 years, for example, we've tortured ourselves over our inability to finish a software project on time and on budget. But as I hinted earlier, this never should have been the supreme goal. The more important goal is transformation, creating software that changes the world or that transforms a company or how it does business. We've been rather successful at transformation, often while operating outside our control envelope. Software development is and always will be somewhat experimental. The actual software construction isn't necessarily experimental, but its conception is. And this is where our focus ought to be. It's where our focus always ought to have been."” Wow - quite radical thinking for an ex-control freak. Am I glad that I've never been an evangelist for XML use in software development, for CORBA and C++ and so on.
- Would the nanotechnologists please stand up?
-
My latest research project deals with the use of virtual worlds for experiments (both virtual and real) in nanotechnology. Being a mere and lowly software hacker I considered it decent to get at least a little book on nanotechnology. Boy was I in for a surprise. There is not such a thing as nanotechnology or nanotechnologists - according to Joachim Schummer, author of "Nanotechnology - Spiele mit Grenzen" , a small booklet (in German). The author explains how the term "nanotechnology" comes from the pop culture and science fiction. Only around the year 2000 the US government - in need for money for basic research in physics and chemistry (non-military) invented nanotechnology as a research and funding area.
Nanotechnology simply is everything that deals with structures between one and one hundred nanometers. Even the name nano has not been popular in the sciences who preferred the term "angstroem" instead (ten of those make one nano). But the term nanotechnology became almost a religion and - due to increased funding - more and more scientific papers showed up with the term in the headline.
Schummer clears up a number of misconceptions around the so called nanotechnology: While the program and sponsors called for it being an interdisciplinary science the reality is that the participating scientists are mostly physicists, chemists and material scientists and they use the methodology of their science and not something vaguely "interdisciplinary". And they do not call themselves "nanotechnologists" but keep their traditional names.
What made the term nanotechnology so important and effective? The sciences behind so called nanotechnology do have some things in common. Especially the price of their toys. This requires serious funding which seems to be impossible without some major publicity in the general population. Beautiful pictures and the aesthetics of things at nano scale, together with wild promises for nanomachines healing blood vessels etc. provided the ground for big spending by eager politicians. Just remember the things Neil Stephensons "matter compiler" was able to produce in "diamond age", the science fiction "bible" of nanotech.
I was really surprised reading about the roots of nanotechnology being in science fiction and popular culture. But then again, why should I worry about it? Virtual worlds also come from popular culture and gaming (and Neil Stephenson wrote its "bible" as well with his science fiction novel "snow crash" in the nineties). And now we are combining both concepts into one big research project with the goal of conducting experiments in nanotechnology.
- Economic reasons for insecure software
-
 You know Joel from the famous JoelOnSoftware blog .
In his book on "the best software writing" the article on "Why not
just block the apps that rely on undocumented behavior?" by Raymond
Chen of Microsft provided a missing link to me: a clear and
convincing tale of economic reasons behind insecure software. The
standard arguments for economic reasons behind insecure software
include the split between profit and risk (those who have to carry
the risks are not the same who make the profit - a frequent pattern
behind risk management) and "bad economic times" which supposedly
make companies cut down on investments for security.
You know Joel from the famous JoelOnSoftware blog .
In his book on "the best software writing" the article on "Why not
just block the apps that rely on undocumented behavior?" by Raymond
Chen of Microsft provided a missing link to me: a clear and
convincing tale of economic reasons behind insecure software. The
standard arguments for economic reasons behind insecure software
include the split between profit and risk (those who have to carry
the risks are not the same who make the profit - a frequent pattern
behind risk management) and "bad economic times" which supposedly
make companies cut down on investments for security.These arguments are rather general and it is not really clear why secure software should be more expensive than insecure or why secure software could not help both sides in a contractual relation.
A first step in a convincing argument for economic reasons behind insecure software can be found in last years talk on Vista security at the black hat conference. Both authors (Dowd and Sotirov) show in detail how Vista security features like address space randomization are made useless. Old versions of libraries frequently require fixed positions in memory. Sofware companies are - according to Microsoft - reluctant to compile their libraries with security options to e.g. set canaries for stack protection. In other words the Microsoft kernel needs to juggle old software in various ways to keep it running. The price of this backward compatibility is that new security features are rendered useless.
If we could now explain why backward compatibility is such an important feature that Microsoft will accept security problems to keep it up and why companies are reluctant to upgrade their software then we are done. And the article by Chen does exactly this: Raymond Chen explains Microsoft's focus on backward compatibility with a simple question: Would you buy a new Windows versions knowing that your existing software won't run anymore? And why on the other hand should game companies who make their profit in the first three or four months in the life of a new game be interested in updating old software for free? Just to make it safer? Gamers would not pay for such an update without new game features.
It is a classic conflict of interest between Microsoft and software vendors. And the buying habits of consumers don't help either.
- Social Computing, social GUIs
-
I finally got around reading more of Joel Spolsky's books. You know Joel from the famous JoelOnSoftware blog
. Though the books include many
articles from the blog it is simply nice to have them in book
form.The one on "the best software writing I" contains many articles
from other authors as well and I believe Joel has chosen well. You
will find the famous "why starbucks does not use two-phase commit"
from Gregor Hohpe and many others. The one article on "Why not just
block the apps that rely on undocumented behavior?" by Raymond Chen
of Microsft provided a missing link to me: a clear and convincing
tale of economic reasons behind insecure software. And the two
articles by Clay Shirky on groups, group behavior and social
software were an excellent foundation for some articles on new user
interfaces which I found in "Joel on Software" and "More Joel on
Software". Those books contain his own articles e.g. about user
interface design for social applications, how to run a software
development shop and a very interesting and slightly disturbing
article on how Joel decided that a master in computer science was
not for him...But here I'd like to talk about social computing and social GUIs and I will start with Clay Shirky. He was probably the first to really understand social computing: it happens when the relation is no longer between a user and her computer but between a user and her group, only mediated by her computer and some social software running on some site. Shirky observerd group behavior (also destructive) and formulated some rules and laws for social software. He also mentioned that groups usually don't scale well - there are only so many people you can have a relation with. It is interesting to watch how facebook and their likes are trying to push those numbers via social software. As I am currently working on ultra-large scale sites (mostly social sites) this was an interesting observation for me. But
But after finishing Clay's articles you absolutely have to read Its not just usabiilty and Building communities with software from Joel himself. It shows you how usability must nowadays include the social functions of the GUI, not its mere usability for the one person in front on the computer. How e.g. to design a GUI to minimize damage by destructive behavior. How to not let the UI encourage negative behavior or support flame wars etc.
Only then did I realize how much more usability is in the context of social software and how much social and psychologica know how is needed to design social software properly. But it goes even further. In the last term a group of my students built a very large multi-touch device and when I watched users interacting with it I realized that the GUI has changed again: Now the group is actually in front of the medium. The GUI needs to reflect the needs of those groups and - depending on the social situation - create different possibilities for group formation, protection (Shirky) and connection to other groups.
This made me specify a research project for this term which has a focus on investigating social behavior with multi-touch devices in different social settings and situations.
- Beautiful Security
-
After reading Andy Oram's famous collection of Peer-to-Peer software some years ago I have become a reader of Oreilly's "beautiful.. " series including beautifl code, beautiful architecture. And now "beautiful security". It contains a number of articles written by security specialists covering a fast area of security problems and solutions. The first article is on pschological security traps and author Peter "Mudge" Zatko lists various traps like confirmation traps (e.g. analyst not questioning previous results because their authors are now her superiors), functional fixations (things can be used only for the intended purpose) and rationalizing away capabilities (a small group of hackers cannot do ...).
Some other memorable articles were the one by Benjamin Edelman on "Securing Online Advertising: Rustlers and Sheriffs in the New Wild West" where the connections between advertising agencies, spammers and malware are investigated. Phil Zimmerman writes about the web of trust in PGP and distinguishes trust and validity in the process of certifiying other certificates. Other topics are: security metrics, the future of security (a rather weak article in my eyes), logging, secure software (on business modells, not technology).
All in all a nice collection but I missed something new, something going beyond what we already know. Something that really channelnges the security-industrial complex of makers of bad operating systems, languages and applications and those selling us virus checkers.
- Classic Requirements Engineering: An Ill posed problem?, more...
-
In a book on modeling and simulation I came across the definition of what makes a "proper problemspecification". I will spare you the details except for one: a proper problem is based on an initial configuration that leads in a uniformly continuous way to a solution. "Inverse problems" are one example of ill posed problems. They work exactly the other way round: the solution or result is a given and we need to find the initial parameters (configuration) which will in turn again lead to the result - a particularily difficult problem to solvee. It requires finding the proper input parameters in a trial and error way and one can only hope that the selection process will converge soon. Needless to say that this process is harder and more expensive than a forward progressing problem.
It then struck me that the way the software community deals with requirements constitutes exactly an ill posed problem: business is supposed to come up with requirements (hopefully as detailed and specific as can be which is in itself a costly and hard problem) and software engineering is supposed to come up with a configuration and process which will exactly reproduce the solution mapped out in the requirements document.
There are two things notable about this procedure. First, we are doing it the hardest way possible: The more detailed the requirements are, the harder the selection process for the initial parameters will be.
And second, those requirements are only so specific and detailed because of the way they are produced, NOT by necessity.
Let me give you a typical example from the world of corporate publishing. Let's say a new homepage needs to be created. Business will talk to some design company and will finally give an order to design the new homepage. What comes back is a design that is detailed down to the pixel position level. But this precision is NOT derived from company internal necessity. It is specific because the designers have to place things within a screen coordinate space. The precision is artificial.
Given a forward processing architecture based on XML/XSL this artificial precision of the target solution results in a tedious and expensive successive approximization done during development.
What do we learn from inverse problems in the context of requirements management? That the current way of thinking in terms of fixed apriori requirements created by the business makes development both slow and expensive. Much better is what agile development proposes: that business and IT works together on requirements to avoid the backward ways of inverse problem specification.
Why are inverse problems so hard to solve? I think that the major reason for it lies in the fact that the transformations involved in going from a problem specification to a solution an not bi-jective, which means the transformations loose information and trying to go back leads to ambiguous situations. Alberto Tarantola's book on Inverse Problem Theory and Methods for Model Parameter Estimation shows statistical methods (monte carlo etc.) to solve inverse problems.
- Beautiful Architecure
-
The new book on Beautiful Architecture: Leading Thinkers Reveal the Hidden Beauty in Software Design
 by Diomidis Spinellis and Georgios
Gousios (O'Reilly Media) contains very good articles on various
kinds of software architectures.
by Diomidis Spinellis and Georgios
Gousios (O'Reilly Media) contains very good articles on various
kinds of software architectures.I do not like very abstract talks on architecture and its systematizations so I will skip the introduction and go straigth to the first paper. It is by Jim Waldo of Sun - famous for his critque of transparency in distributed systems. But in this paper he turns around and claims that for his new project (Darkstar, the 3D game engine platform) it was necessary to build transparent distributed features because of the special environment of 3D games. He claims that game programmers are unable to deal e.g. with concurrency explicitly. Darkstar splits requests into short and limited tasks which can be transparently distributed to different cores or machines.
To achieve consistency all data store access is transacted with an attached event system. We will see how this scales in the long term.
The next paper by Michael Nygard describes the development of an image processing application used throughout hundreds of stores in the US where regular people can bring in their pictures and have them printed in various forms and formats. Here the main problem was that the main operators of the system were non-technical and in some cases even customers. For me the most interesting bit was when he described using Java NIO for image transport between store workstations and store servers. Image transport had to be highly reliable and very fast too. Nygard mentioned that this part of the project took rather long and showed the highest complexity within the project. Just matching the NIO features with high-speed networks and huge amounts of data was critical. He said that e.g. using one thread for event dispatch and manipulation of selector state is safe but can lead to performance problems. The thread used to only read a small amount of data from one channel, distribute it and go to the next channel. The high-speed network was able to deliver data so fast that this scheduling approach led to severe stalls on the network layer. They had to change the scheduling so that the receiving thread now reads data from one channel as long as there are data available. But of course this is only possible with few clients pushing files to your server. With more clients this can stall those clients considerably. Not to forget the problem of denial-of-service attacks when clients realize the way you are scheduling reads...
It has taken us a long time to understand how web applications should communicate. It is via the REST architectural style which leads to high scalability and lose coupling. Brian Sletten does an excellent job in explaining the separations of concerns defined in REST. Things, actions and formats are all that is needed. He shows how to build pipelines of resource oriented applications.
What is Facebook really? It is a dispatcher of social information to other applications and users. Dave Fetterman of Facebook eplains the data centric architecture of Facebook and how it evolved into a federated engine able to integrate other applications and giving them controlled access to user data. Several critical aspects of software construction are discussed: lose coupling, data access and query language construction, generative approaches for consistency etc. A federated authentication system much like liberty alliance (based on bouncing requests forward and backward between external servcices and facebook playing an identity provider) has been implemented. This was needed of course to prevent users from exposing their facebook passwords to other services.
The section of system software contained articles on Xen, Jikes (a meta-circular JVM), the guardian fault-tolerant OS and - my favourite - JPC: An x86 PC Emulator in Pure Java by Rhys Newman and Christopher Dennis. Perhaps because a long time ago I wrote such an Emulator myself. The article is an excellent introduction to building a VM and explains extremely efficient code generation. You can learn interesting things about java performance too, e.g. the speed of case statements depending on the distribution of the values and how to construct efficient pageing algorithms. Pure fun to read.
The next section on application development contained two papers on emacs and KDE/arconadi development. They presents lots of good architectureal decisions, e.g. the introduction of ThreadWeaver - a scheduling component that shields developers from dealing with multithreaded tasks.
Finally, in Languages and Architecure, Bertrand Meyer shows that functional programming can and should be integrated with OO concepts. A demonstration of the visitor pattern explains how closures (delegates, agents, higher-order functions) turn the pattern into a customizable runtime component. Meyer also shows that naive functional solutions can lead to function explosion.
The last article by Panagiotis Lourides has the title "Reading the classics". It starts with a demonstration of the beauty behind squeak (smalltalk) and its abstractions. I like the article a lot because the author also pointed out that architectures need to compromise as well if we should be able to use them. He ended with some nice examples from real architecture. fallingwater (Daderot, CC0 1.0 no copyright) was created by the famous architect Frank Lloyd Wright and supposedly is the most frequently illustrated house of the 20th century. Built over a waterfall the house reflects this in its own architecture. But Lourides also cites the bad sides of this wonderful architecture: it created a house that was unlivable due to mildew, water leaks and structural damage to the concrete.
 (picture thanks to wikipedia commons)
(picture thanks to wikipedia commons)This emphasizes an important point of architecture: Architecture should not be considered something absolute. It is not a religious thing and fanatics are dangerous in software architecture just as anywhere else. Architecture needs to fit to the team using it, to the users living with it and the environment which embeds it.
- Performance Testing and Analysis
-
During my preparations for a master course on reliability, scalability, availability and performance in distributed sysetms I stumbled over a new book from Oreilly: The Art of Application Performance Testing: Help for Programmers and Quality Assurance by Ian Molyneaux
 is a short and easy to read
introduction to performance testing. It explains how to setup tests
and discusses basic problems of load generation and measurements.
The chapter I liked most was the one on root cause analysis where
the author showed how so called key performance indicators (e.g. cpu
load, disk time) are combined with the number of virtual users to
show capacity bottlenecks.
is a short and easy to read
introduction to performance testing. It explains how to setup tests
and discusses basic problems of load generation and measurements.
The chapter I liked most was the one on root cause analysis where
the author showed how so called key performance indicators (e.g. cpu
load, disk time) are combined with the number of virtual users to
show capacity bottlenecks.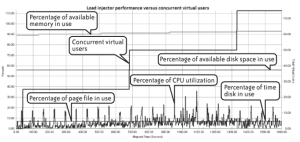
The book takes you be the hand and shows how to start performance testing using templates and kpi's. As it is rather short it cannot go into the details of architectures much. At a certain point - when testing changes into analysis - you will be forced to get a better understanding of the architectures involved, e.g. the critical performance points within an application server. At that point your work is highly product dependent. For performance analysis and testing within a websphere environment certain ibm redbooks might be helpful. My favourite is WebSphere Application Server V6 Scalability and Performance Handbook with its numerous tools and strategies like ThreadAnalyzer, Heap analyzers etc.,most of which can be used also in non-WAS environments.
If have been called in several times when an application showed poor performance or strange defects. The bad news with respect to performance is that finding the problems usually requires a deep understanding of the architecture of the application as well as the components and products involved. And usually you will need to get into the application by running debuggers, tracers etc.
What I frequently noticed is that the application owners have either no idea at all about the possible culprits for the low performance or come up with a rather fixed opinion on where the fault is - without a sound empirical base to prove their assumption.
In reality the possible causes for poor performance are numerous. I have seen almost everything from virtual machine bugs to external services not being available (causing stalled threads) to serious misunderstandings of transaction models causing a slow lockup of the datastore over several hours to missing indexes and generally badly constructed queries. The problem is to find a procedure which will finally lead you to the culprit. Here are some things you will need for this:
Create an overall architecture diagramm which displays the tiers and components where data flow through. This shows you also interception points and gives an idea of the distribution architecture of the system. The next step is chosing some key transactions or requests and measuring them tier by tier. If things point towards the application server as containing the problem debugging and tracing of the VM is in order, using the new virtual machine debugging interfaces provided by modern VMs.
This leads to detailed statistics for requests and per thread performance analysis. An important part is tracking the memory use for requests: Is there a possible memory leak? Excessive object creation?
Sometimes you might find something extraordinary here but in many cases you will end up with looking at the way the datasores are accessed. You need to realize that the days when application teams always had a DB specialist with them are long over. Nowadays those specialists are too expensive to be part of each application project and sometimes they are centralized within a consulting team, sometimes they are called in on a case by case (or should I say problem by problem?) base. In either case, they do not understand much about the application and the application developers do not understand much about the database. And it shows: missing indexes and poorly constructed queries are in many cases the reasons behind poor application performance. And never - really NEVER - is it the programming language used. Poor use of a programming language can have an influence though.
If you are after a better theoretical foundation of performance and throughput questions you will need to take a look at queuing theory and its concepts. A paper by Henry H. Liu of BMC on Applying Queuing Theory to Optimizing Performance of Enterprise Software Applications is a good starting point. Guerrilla Capacity Planning: A Tactical Approach to Planning for Highly Scalable Applications and Services by Neil J. Gunther shows practical applications of it.
- Finally XSS on kriha.org as well,...
-
Finally I have also succumbed to the temptations of the dynamically insterted script tag (:-). I wanted to have a comment tracking system and Marc Seeger pointed me to disqus.com . They didn't have customizable code for non-standard blogs like mine until last Thursday. I took the code and integrated it into my xml-to-html generator (xslt transformation) and it looks like it works. I've put the comments into the sidebar. Unfortunately disqus takes one page as the lowest granularity and that means there is only one comment section per page. Works well on most of my pages except the blog..
And while I learned to love the script tag I decided to do something about the usuability (or should I say unusability) of kriha.org and followed Arnold Kleitsch's advice to use Google Analytics. Another piece of javascript added to my xsl driver file and here they were: the first numbers from Google Analytics. Thirteen visits with an astonishingly high bounce rate (and a terrifyingly short time spent on kriha.org). I hear Kleitsch mumbling something about "landing page, landing page"...
- On academia vs. industry, digital rituals and user data and the spirit of google university,...
-
I got to read quite a lot during my research term and stumbled over some nice quotes lately. The first is from Werner Vogels of allthingsdistributed.com who is now the CTO of Amazon. I know him from a long time ago when the distobj mailing list was still functional...“A question I get asked frequently is how working in industry is different from working in academia. My answer from the beginning has been that the main difference is teamwork. While in academia there are collaborations among faculty and there are student teams working together, the work is still rather individual, as is the reward structure. In industry you cannot get anything done without teamwork. Products do not get build by individuals but by teams; definition, implementation, delivery and operation are all collaborative processes that have many people from many different disciplines working together. ” I couldn't have said it any better. It is the reason why I still work in the industry as well. And it signifies one of the big problems in university education.
The second quote is from the cover of the universtiy of google by Tara Brabazon . “University teaching is a special job. It is a joy to wake up in the morning knowing that during each working day, an extraordinary event or experience will jut out from the banal rhythms of administration, answering emails and endlessly buzzing telephones. Students, in these ruthless times, desperately want to feel something, anything beyond the repetitive and pointless patterns of the casualized workplace and the selection of mobile phone ring tones. This cutting consumerism subtly corrodes the self. These students follow anyone who makes them feel more than a number, more than labour fodder for fast food outlets. I believe in these students, and I need to believe that the future they create will be better than the intellectual shambles we have bequeathed them. Being a teacher is a privilege to never take for granted. The bond between students and educators is not severed when a certificate is presented. We share a memory of change, of difference, of feeling that we can change the world, one person at a time.” I wonder if anything in our ongoing university reform and improvement processes does support the spirit in this quote.
Finally, a nice memo from the former CEO of Fotolog.com, John Borthwick. Taken from his blog THINK/Musings . “#Positioning matters When I started at Fotolog one of the early set of discussions we had was about positioning what is Fotolog? what does the brand represent to our members and what is the relationship our members have to the experience? Fotolog had for a long time been considered as an international version of Flickr. Yet when we looked at the usage data it was radically different to Flickr. Yesterday, to take a random data point 6% of all the people who ever signed up to Fotolog uploaded a photo to the site, thats a degree of engagement beyond Flickr and many other photo sites (870k pictures, one picture per member, 13.9M members translates into 6.3% of the total membership). Last month comscore tracked Fotolog users as spending 26 min on the site, per day, Flickr's numbers are less than a quarter of that number. By digging into usage data we concluded that the Fotolog experience was social, social media. Understanding this helped us orientate our positioning for our members, our advertisers and ourselves. The rituals associated with digital images are slowly taking form - and operating from within the perspective of a mature analog market (aka the US) tends to disort one's view of what how digital imagery is going to be used online. The web as a distinct medium is developing indigenous means of interactions. We figured out the positioning, summarized it in a short phrase (share you world with the world), put together a banner with 1.. 3 steps to get going on Fotolog and got to work. Clear positioning helped us, and helped our partners figure out what we were and what we weren't.”. First, look at user data and realize what your users REALLY do on your site. Second, create and foster the rituals necessary for user collaboration (watch out: he is not talking about "services". He talks about a deep understanding of your users, their actions in a new technical area). Third, don't kill new developments with old experiences - even successful ones.
The memo of John Borthwick contains more excellent and surprising facts about the business development of a large community site. Read it and while you are at it go to www.highscalability and read the piece on "secrets of Fotologs Scaling Success" which adds some technological advice.
- The Deadline - Tom DeMarco on Project Management
-
It is quite unusual to put findings on project management into the literary form of a novel. But Tom DeMarco did just that with "The Deadline" and continued the success of his previous "Peopleware" book. As it is always with complex and "soft" things the pure list of do's and dont's wont help you initially because the context makes all the difference in social engineering - and that's what project management is all about. To take a look at the rules anyway click on the book link in the sidebar.
With of the things told be DeMarco I could immediately sympathize e.g. with the futility of pressure or management by fear. Only the rule to delay coding until the very end of a project and spend much more time in design sounds critical to me. But if you subsume unit tests, architecture tests etc. all under design it might be OK.
The most important tool for good project management seems to be the "hunch". Also called gut-feeling. Those "hunches" tell you about problems to come (e.g. whether two people might be incompatible). But Tom DeMarco shows that there are ways to test and investigate the quality of you hunches even further by using modeling and simulation tools like Stella or Vensim. These tools let you create a simple model of a situation including actors, influences etc. And they show you how these things can develop over time. This is where many of our hunches tend to be a bit imprecise.
I spent a whole day looking up information on modeling and simulation tools for complex environments (meaning above technical algorithms) and I will try to use some for large system modeling next term. Surprinsingly I ended up looking at sites like System-Thinking.org or sites about operational research, learning organizations, complexity research etc.
I allways found DeMarcos books on project management and software development to be the closest to my own experiences. He does not shy away from destroying managerial nonsense about how projects really work.
- Disqus Comment Section
-
I am still trying to figure out a better way to integrate with disqus.
- Previous Year
-
This leads to the blog entries from the previous year. Or check the left side navigation for other years.
| $Date: 2009/01/01 14:07:15 $ | Home | About... | Privacy... | Feedback |
Copyright © 2001-2015  Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution 2.5 License by Walter Kriha. Except where otherwise noted, content on this site is licensed under a Creative Commons Attribution 2.5 License by Walter Kriha. | ||